Showing of 1 until 15 from 210 result(s)
Search for: Corneal topography; Statistical analysis; Neural networks (computer); Artificial intelligence; Discriminant analysis
12-tab01tb.jpg)
Abstract
Objetivo: A refração pós-operatória na cirurgia moderna de catarata por microincisão ganha ainda mais importância em pacientes com cirurgia prévia de ceratomileuse in situ assistida por laser (LASIK). As alterações astigmáticas induzidas cirurgicamente nesses olhos podem diferir não apenas em magnitude, mas também em direção em comparação com córneas virgens. O objetivo deste estudo foi comparar as alterações astigmáticas induzidas cirurgicamente após cirurgia de catarata por microincisão entre córneas pós-LASIK e olhos virgens.
Métodos: Foi revisada uma série de casos de cirurgia de catarata por microincisão em olhos com e sem cirurgia LASIK anterior. Os dados demográficos, o comprimento axial no momento da cirurgia de catarata, a espessura central da córnea, os valores esféricos e cilíndricos, as leituras da ceratometria e o astigmatismo corneano posterior pós-operatório foram avaliados retrospectivamente. O método Alpins modificado foi usado para análise vetorial astigmática e foram avaliados o astigmatismo basal, o astigmatismo induzido cirurgicamente, o vetor de diferença, o efeito de achatamento e o torque.
Resultados: Ao todo, 42 olhos de 24 indivíduos foram avaliados. O Grupo I consistiu em 14 olhos com LASIK prévio; o Grupo II incluiu 28 olhos sem qualquer cirurgia refrativa. A média da espessura corneana central pré-operatória no Grupo I foi significativamente mais fina (p=0,012). Não houve diferença significativa no astigmatismo basal entre os grupos em termos de magnitude e vetores de potência. Após a cirurgia de catarata por microincisão, não houve diferenças significativas nos valores médios esféricos, cilíndricos e leituras médias de ceratometria (todos com p>0,05). No entanto, o astigmatismo induzido cirurgicamente e o vetor de diferença foram significativamente maiores no componente do vetor J45 em olhos pós-LASIK, e o efeito de aumento da inclinação pela cirurgia de catarata por microincisão nas córneas pós-LASIK foi significativo em comparação com olhos virgens (p=0,001, p=0,002 e p=0,018, respectivamente).
Conclusões: A cirurgia de catarata aumentou a inclinação das córneas em ambos os grupos, sendo esse aumento significativamente maior nos olhos pós-LASIK. Certamente, a topografia da córnea antes da cirurgia de catarata é particularmente útil para fornecer interpretações mais precisas do astigmatismo induzido cirurgicamente.
Keywords: Cirurgia de catarata; Ceratomileuse; excimer laser in situ; Cirurgia refrativa; Astigmatismo induzido cirurgicamente; Análise vetorial.
02-fig01.jpg)
Abstract
OBJETIVO: Determinar o efeito da blefaroplastia superior na topografia corneana e no cálculo do poder das lentes intraoculares usando Galilei e IOLMaster.
MÉTODOS: Trinta pacientes submetidos a blefaroplastia superior de maio de 2014 a março de 2017 no Hospital Oftalmológico de Sorocaba, São Paulo, Brasil foram incluídos neste estudo de série de casos observacional. Todos os pacientes foram submetidos a sessões de imagem com Galilei e IOLMaster antes da cirurgia (exame de base) e no 1º e 6º mês pós-operatório. Os resultados primários utilizando os dois aparelhos incluíram ceratometria, astigmatismo corenano e astigmatismo corneano induzido pela blefaroplastia. O comprimento axial e o cálculo do poder da lente intraocular foram realizados unicamente com o IOLMaster (fórmula de Holladay). Teste-t pareado e análise vetorial foram usados na análise estatística.
RESULTADOS: Sessenta olhos de 30 pacientes foram incluídos prospectivamente. A análise vectorial mostrou que após 6 meses da cirurgia, a blefaroplastia superior induziu na média 0,39 D de astigmatismo corneano medido com o Galilei e 0,31 D com IOLMaster. As medidas com o IOLMaster mostraram que a ceratometria média (44,56 vs 44,64 D, p=0,01), ceratometria máxima (45,17 vs 45,31, p=0,01) e o astigmatismo corneano (1,22 vs 1,34, p=0,03) foram maiores após 6 meses da blefaroplastia. As medidas com IOLMaster mostraram que o poder da lente intraocular foi significativamente menor 6 meses após a blefaroplastia (22,07 vs 21,93, p=0,004). Todos os outros parâmetros não mostraram mudanças entre o pré-operatório e o 6º mês da cirurgia (p>0,05 para todas as comparações).
CONCLUSÕES: A blefaroplastia superior influenciou o cálculo da lente intraocular utilizando o IOLMaster. Contudo, a influência não foi clinicamente significativa. Não foram encontradas mudanças topográficas com o Galilei.
Keywords: Blefaroplastia; Lentes intraoculares; Ceratometria; Topografia da córnea; Biometria
02-fig01tb.jpg)
Abstract
Objetivo: O comprimento da membrana de Descemet e o tamanho do enxerto doador na ceratoplastia lamelar anterior profunda não coincidem em córneas muito íngremes, o que pode levar às dobras da membrana de Descemet. O objetivo deste estudo é estabelecer um modelo teórico para cálculo do tamanho do enxerto para ceratoplastia lamelar anterior profunda e avaliar a sua eficácia na prevenção de dobras da membrana de Descemet.
Métodos: Calculamos o diâmetro do arco do leito receptor usando a fórmula do cosseno e desenvolvemos uma tabela para auxiliar os cirurgiões na seleção do tamanho da punção no doador. Para testar a utilidade dessa fórmula, avaliamos o desenvolvimento das dobras da membrana de Descemet em pacientes com ceratocone com córneas muito íngremes (K>60D). No grupo 1, foram realizadas cirurgias de ceratoplastia lamelar anterior profunda, utilizando tamanhos de enxerto que foram determinados com base em nosso modelo (n=31). No grupo 2, os tamanhos dos enxertos foram determinados com base no julgamento empírico do cirurgião sem qualquer cálculo formal (n=30).
Resultados: Nossos cálculos teóricos demonstraram que o diâmetro dos tamanhos da punção do doador necessários para evitar as dobras na membrana de Descemet aumenta quando a córnea é mais íngreme ou o tamanho da trefina é maior. Testamos a eficácia deste modelo no resultado clínico da ceratoplastia lamelar anterior profunda. A média de idade (28,9 ± 10,1 anos vs. 32,8 ± 8,3 anos, p=0,11) e K1 pré-operatório (59,2 ± 9,3 D vs. 58,1 ± 9,4 D, p=0,67), K2 (66,2 ± 6,0 D vs. 65,7 ± 7,4) D, p=0,81) e Km (62,1 ± 7,7 D vs. 61,8 ± 8,1 D, p=0,88) foram semelhantes entre os dois grupos. Três pacientes desenvolveram dobras na membrana de Descemet no grupo 2, e nenhum dos pacientes desenvolveu dobras na membrana de Descemet no grupo 1. Estes resultados apoiam nossos cálculos teóricos.
Conclusão: O ajuste do tamanho do enxerto doador com base no diâmetro do arco calculado do leito receptor reduziu o desenvolvimento das dobras na membrana de Descemet após ceratoplastia lamelar anterior profunda em córneas íngremes.
Keywords: Membrana de Descemet; Ceratocone; Ceratoplastia penetrante; Topografia da córnea; Córnea/patologia
08-fig01.jpg)
Abstract
Objetivo: Desenvolver um aplicativo (TopEye) na plataforma iOS para dispositivos móveis que possibilite a captação e interpretação do mapa de cores gerados por qualquer topógrafo corneano através da inteligência artificial (IA).
Métodos: A execução, acompanhamento e avaliação do projeto foi utilizada a metodologia Scrum, processo de desenvolvimento interativo e incremental para gerenciamento de projetos e desenvolvimento ágil de software. O banco de padrões de diagnóstico gerado consiste em 1172 exemplos, divididos em: 275 padrões esféricos, 302 regulares simétricos, 295 regulares assimétricos e 300 irregulares (ceratocone). Para o desenvolvimento da inteligência artificial do aplicativo, foi estabelecido o treinamento da rede com 240 imagens de cada tipo de padrão, totalizando 960 (81,91%) padrões. O restante das imagens, 212 (18,09%), foram utilizadas para testar o aplicativo e usadas para gerar os resultados. O processo é semiautomático, assim a captação da imagem topográfica é realizada com smartphone, o examinador realiza o contorno do relevo corneano manualmente para em seguida a rede neural realizar o diagnóstico.
Resultados: O aplicativo diagnosticou 201 (94,81%) imagens corretamente. De um total de 212 imagens, o algoritmo errou a classificação de apenas 11 (5,19%). A principal ocorrência de erro foi na distinção das classes simétrica e assimétrica. No rastreio do ceratocone o aplicativo alcançou 95,00% de sensibilidade e 98,68% especificidade.
Conclusão: O trabalho resultou na obtenção de um aplicativo eficiente na captura da imagem topográfica pela câmera do smartphone e na interpretação da mesma através da inteligência artificial aplicada.
Keywords: Dispositivos móveis; Inteligência artificial; Topografia corneana; Astigmatismo
Abstract
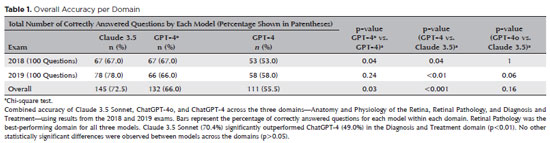
PURPOSE: Natural language models and chatbots, particularly OpenAI’s Generative Pre-Trained Transformer architecture, have transformed human interaction with digital interfaces. The latest versions, including ChatGPT-4o, offer enhanced functionalities compared to their predecessors. This study evaluates the accuracy of ChatGPT-4, ChatGPT-4o, and Claude 3.5 Sonnet in answering questions from the Brazilian Retina and Vitreous Society certification exam.
METHODS: We compiled 200 multiple-choice questions from the Brazilian Retina and Vitreous Society 2018 and 2019 exams. Questions were categorized into three domains: Anatomy and Physiology of the Retina, Retinal Pathology, and Diagnosis and Treatment. Using a standardized prompt developed according to prompt design guidelines, we tested ChatGPT-4, ChatGPT-4o, and Claude 3.5 Sonnet, recording their first responses as final. Three retina specialists performed a qualitative analysis of the answers. Accuracy was determined by comparing responses to the official correct answers. Statistical analysis was conducted using chi-square tests and Cohen’s Kappa.
RESULTS: Claude 3.5 Sonnet achieved the highest overall accuracy (72.5%), followed by ChatGPT-4o (66.0%) and ChatGPT-4 (55.5%). Claude 3.5 Sonnet and ChatGPT-4o significantly outperformed ChatGPT-4 (p<0.01 and p=0.03, respectively), while no significant difference was observed between Claude 3.5 Sonnet and ChatGPT-4o (p=0.16). Model responses agreed 74.5% of the time, with a Cohen’s κ of 0.47. Retinal Pathology was the best-performing domain for all models, whereas Anatomy and Physiology of the Retina and Diagnosis and Treatment were the weakest domains for Claude 3.5 Sonnet and ChatGPT-4, respectively.
CONCLUSIONS: This study is the first to assess Claude 3.5 Sonnet, ChatGPT-4, and ChatGPT-4o in retina specialist certification exams. Claude 3.5 Sonnet and ChatGPT-4o significantly outperformed ChatGPT-4, highlighting their potential as effective tools for studying retina specialist board exams. These findings suggest that the enhanced functionalities of Claude 3.5 Sonnet and ChatGPT-4o offer substantial improvements in medical education contexts.
Keywords: Artificial intelligence; ChatGPT; Retina; Medical education; Ophthalmology, Large language model; Natural language processing
Abstract
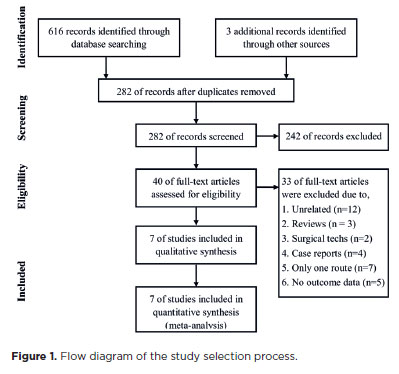
PURPOSE: To compare the incidence rates of complications following pediatric cataract surgery between the limbal and pars plana approaches.
METHODS: PubMed, EMBASE, Web of Science, Scopus, Cochrane Library, and ClinicalTrials.gov were systematically searched for studies comparing the two surgical approaches. We pooled the incidence rates of postoperative complications using a random-effects model.
RESULTS: Seven studies comprising 375 eyes from 260 patients were included. No significant differences in complication rates were observed between the limbal and pars plana approaches. The pooled incidence rates (95% confidence Interval) of postoperative visual axis opacity (VAO), VAO treated with laser or surgery, secondary glaucoma, wound leakage, corneal edema, anterior chamber reaction, posterior iris synechiae, capsular phimosis, intraocular lens dislocation, posterior capsular rupture, and intravitreal lens fragmentation were 4.7% (0.8%10.8%), 3.9% (1.0%-8.1%) , 2.8% (0%-11.4%), 0 (0%-1.3%), 2.9% (0%-11.8%), 5.6% (0.1%-16.5%), 2.4% (0%-8.5%), 3.8% (0.6%-8.9%), 2.2% (0%-6.4%), 9.2% (4.1%-15.8%) and 1.3% (0%-6.3%), respectively. Both surgical approaches demonstrated improved visual acuity postoperatively.
CONCLUSIONS: Pediatric cataract surgery, performed via the limbal or pars plana approach, is effective and safe, with a low incidence of complications when conducted by trained surgeons. Neither method demonstrated a significant difference in the visual acuity improvement or complication rates.
Keywords: Pediatric cataract surgery; Postoperative complications; Limbal route; Pars plana routes; Meta-analysis
Abstract
PURPOSE: We developed an artificial intelligence program for calculating intraocular lenses and analyzed its accuracy rate via ultrasonic biometry. This endeavor is aimed at enhancing precision and efficacy in the selection of intraocular lenses, particularly in cases where optical biometry is unavailable.
METHODS: Data was collected from the Hospital de Clínicas de Porto Alegre, which included cases of phacoemulsification with intraocular lens implantation, in which the lens selection was based on ultrasonic biometry. The program, implemented in Python, Java, and PHP, employs the ridge regression method. Two design options were developed: a basic model, which uses only keratometry variables (K1 and K2), axial size and final target refraction in the spherical equivalent, and an advanced model, which incorporates preoperative refraction and the patient's age. The Universal Barrett II formula was used to compare both models.
RESULTS: The sample consisted of 486 eyes from 313 patients, with 350 eyes used for program training and 136 for program validation. The spherical equivalent hit rates, with a variation of ±0.5 D, were 86% and 87.5% for the basic and advanced models, respectively, with no statistically significant difference between them. With the Barret Universal II formula, the success rate was 69%, which was significantly different from the values of the two aforementioned models (p<0.0001). The system was better for medium and long eyes but worse for short eyes (<=22.00 mm).
CONCLUSION: The developed artificial intelligence program was superior to the Barrett formula in terms of performance, in the general context and within the subgroup of patients with longer eyes. This innovation can considerably contribute to the selection of intraocular lenses, particularly in cases where optical biometry is unavailable.
Keywords: Biometry; Intraocular lens; Cataract; Artificial intelligence
Abstract
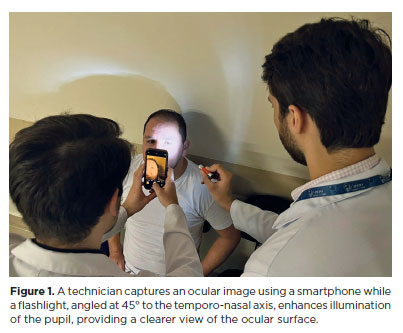
PURPOSE: This pilot study evaluated the diagnostic accuracy of a deep learning model for detecting pterygium in anterior segment photographs taken using smartphones in the Brazilian Amazon. The model’s performance was benchmarked against assessments made by experienced ophthalmologists, considered the clinical gold standard.
METHODS: In this cross-sectional study, 38 participants (76 eyes) from Barcelos, Brazil, were enrolled. Trained nonmedical health workers captured high-resolution anterior segment images using smartphones. These images were analyzed using a deep learning model based on the MobileNet-V2 convolutional neural network. Diagnostic metrics–including sensitivity, specificity, accuracy, positive predictive value, negative predictive value, and area under the receiver operating characteristic curve–were calculated and compared with the ophthalmologists’ evaluations.
RESULTS: The deep learning model achieved a sensitivity of 91.43%, specificity of 90.24%, positive predictive value of 88.46%, negative predictive value of 92.79%, and an area under the curve of 0.91. Logistic regression revealed no statistically significant association between pterygium and demographic variables such as age or gender.
CONCLUSIONS: The deep learning model demonstrated high diagnostic performance in identifying pterygium in a remote Amazonian population. These preliminary findings support the potential use of artificial intelligence–based tools to facilitate early detection and screening in underserved regions, thereby enhancing access to ophthalmic care.
Keywords: Pterygium/diagnostic imaging; Smartphone; Diagnostic techniques, ophthalmological; Deep learning; Telemedicine; Artificial intelligence; Cross-sectional studies; Brazil/epidemiology
Abstract
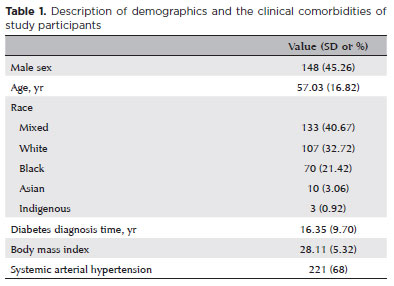
PURPOSE: Diabetic retinopathy screening in low- and middle-income countries is limited by restricted access to specialized care. Portable retinal cameras offer a practical alternative; however, image quality – affected by mydriasis – directly influences the performance of artificial intelligence models. This study evaluated the effect of mydriasis on image gradability and AI-based diabetic retinopathy detection in real-world, resource-limited settings.
METHODS: The proportions of gradable images were compared between mydriatic and non-mydriatic groups. Generalized estimating equations were used to identify factors associated with image gradability, including age, sex, race, diabetes duration, and systemic hypertension. A ResNet-200d model was trained on the mobile Brazilian Ophthalmological dataset and externally validated on both mydriatic and non-mydriatic images. Model performance was evaluated using accuracy, F1 score, area under the curve, and confusion matrix metrics. Sensitivity differences were assessed using the McNemar test, and area under the curves were compared using DeLong's test. The Youden index was used to determine optimal classification thresholds. Agreement between macula- and disc-centered images was analyzed using Cohen's κ.
RESULTS: The mydriatic group demonstrated a higher proportion of gradable images compared with the non-mydriatic group (82.1% vs. 55.6%; p<0.001). In non-mydriatic images, lower gradability was associated with systemic hypertension, older age, male sex, and longer diabetes duration. The AI model achieved better performance in mydriatic images (accuracy, 85.15%; area under the curve, 0.94) than in non-mydriatic images (accuracy, 79.68%; area under the curve, 0.93). The McNemar test showed a significant difference in sensitivity (p=0.0001), whereas DeLong's test revealed no significant difference in area under the curve (p=0.4666). The Youden index indicated that optimal classification thresholds differed based on mydriasis status. Agreement between image fields was moderate to substantial and improved with mydriasis.
CONCLUSION: Mydriasis significantly improves image gradability and enhances AI performance in diabetic retinopathy screening. Nonetheless, in low- and middle-income countries where pharmacologic dilation may be impractical, optimizing model calibration and thresholding for non-mydriatic images is essential to ensure effective AI implementation in real-world clinical environments.
Keywords: Artificial intelligence; Bias; Diabetic retinopathy; Portable camera; Retina
Abstract
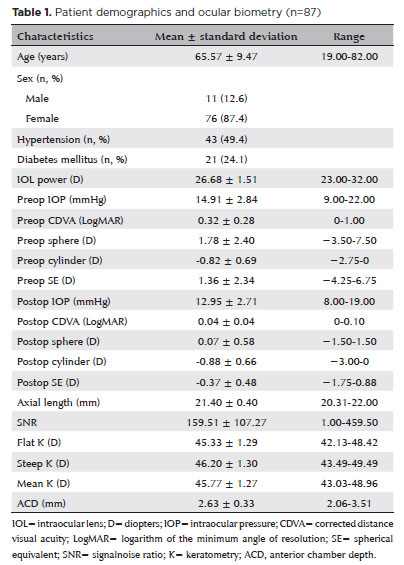
PURPOSE: To compare the refractive prediction error of Hill-radial basis function 3.0 with those of 3 conventional formulas and 11 combination methods in eyes with short axial lengths.
METHODS: The refractive prediction error was calculated using 4 formulas (Hoffer Q, SRK-T, Haigis, and Hill-RBF) and 11 combination methods (average of two or more methods). The absolute error was determined, and the proportion of eyes within 0.25-diopter (D) increments of absolute error was analyzed. Furthermore, the intraclass correlation coefficients of each method were computed to evaluate the agreement between target refractive error and postoperative spherical equivalent.
RESULTS: This study included 87 eyes. Based on the refractive prediction error findings, Hoffer Q formula exhibited the highest myopic errors, followed by SRK-T, Hill-RBF, and Haigis. Among all the methods, the Haigis and Hill-RBF combination yielded a mean refractive prediction error closest to zero. The SRK-T and Hill-RBF combination showed the lowest mean absolute error, whereas the Hoffer Q, SRK-T, and Haigis combination had the lowest median absolute error. Hill-radial basis function exhibited the highest intraclass correlation coefficient, whereas SRK-T showed the lowest. Haigis and Hill-RBF, as well as the combination of both, demonstrated the lowest proportion of refractive surprises (absolute error >1.00 D). Among the individual formulas, Hill-RBF had the highest success rate (absolute error ≤0.50 D). Moreover, among all the methods, the SRK-T and Hill-RBF combination exhibited the highest success rate.
CONCLUSIONS: Hill-radial basis function showed accuracy comparable to or surpassing that of conventional formulas in eyes with short axial lengths. The use and integration of various formulas in cataract surgery for eyes with short axial lengths may help reduce the incidence of refractive surprises.
Keywords: Cataract; Lenses, intraocular; Axial length, eye; Refractive errors; Artificial intelligence
10-fig01tb.jpg)
Abstract
Objetivo: Avaliar o desempenho de classificação de modelos ou arquiteturas de rede neural convolucional pré-treinadas usando um conjunto de dados de imagem de fundo de olho contendo oito rótulos de doenças diferentes.
Métodos: Neste artigo, o conjunto de dados de reconhecimento inteligente de doenças oculares publicamente disponível foi usado para o diagnóstico de oito rótulos de doenças diferentes. O banco de dados de reconhecimento inteligente de doenças oculares tem um total de 10.000 imagens de fundo de olho de ambos os olhos de 5.000 pacientes para oito categorias que contêm rótulos saudáveis, retinopatia diabética, glaucoma, catarata, degeneração macular relacionada à idade, hipertensão, miopia, outros. Investigamos o desempenho da classificação de doenças oculares construindo três arquiteturas de rede neural convolucional pré-treinadas diferentes, incluindo os modelos VGG16, Inceptionv3 e ResNet50 com otimizador de Momento Adaptativo. Esses modelos foram implementados no Google Colab o que facilitou a tarefa sem gastar horas instalando o ambiente e suportando bibliotecas. Para avaliar a eficácia dos modelos, o conjunto de dados é dividido em 70% para treinamento, 10% para validação e os 20% restantes utilizados para teste. As imagens de treinamento foram expandidas para 10.000 imagens de fundo de olho para cada tal.
Resultados: Observou-se que o modelo ResNet50 alcançou acurácia de 97,1%, sensibilidade de 78,5%, especificidade de 98,5% e precisão de 79,7% e teve a melhor área sob a curva e pontuação final para classificar a categoria da catarata (área sob a curva=0,964, final=0,903). Em contraste, o modelo VGG16 alcançou uma precisão de 96,2%, sensibilidade de 56,9%, especificidade de 99,2% e precisão de 84,1%, área sob a curva 0,949 e pontuação final de 0,857.
Conclusão: Esses resultados demonstram a capacidade das arquiteturas de rede neural convolucional pré-treinadas em identificar doenças oftalmológicas a partir de imagens de fundo de olho. ResNet50 pode ser uma boa solução para resolver problemas na detecção e classificação de doenças como glaucoma, catarata, hipertensão e miopia; Inceptionv3 para degeneração macular relacionada à idade e outras doenças; e VGG16 para retinopatia normal e diabética.
Keywords: Redes neurais de computação; Aprendizado profundo; Processamento de imagem assistida por computador; VGG16; Inceptionv3; ResNet50; Fundo de olho; Oftalmopatias.
Abstract
PURPOSE: To assess the performance of a contemporary large language model (ChatGPT-5) against ophthalmology residents on a standardized set of glaucoma multiple-choice questions.
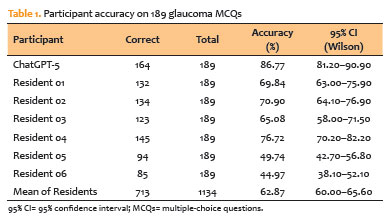
METHODS: We conducted a cross-sectional comparative study with 189 text-only glaucoma multiple-choice questions from the Cybersight question bank. ChatGPT-5 was tested under standardized conditions, with each item placed in a new chat and limited to letter-only outputs. Six ophthalmology residents from a Brazilian training program (two Postgraduate Year 1, two Postgraduate Year 2, and two Postgraduate Year 3) answered the same questions under supervision. Accuracy was calculated using the official key. McNemar’s exact test was used to compare items between ChatGPT-5 and residents, and matched odds ratios and 95% confidence intervals (95% CIs) were calculated using the Haldane–Anscombe correction.
RESULTS: ChatGPT-5 received 164 of 189 correct responses (86.8%; 95% CI, 81.2–90.9). Residents’ overall accuracy was 62.9% (713/1,134; 95% CI, 60.0–65.6). The top-performing resident earned 76.7%. ChatGPT-5 outperformed all residents in head-to-head comparisons, with odds ratios ranging from 1.84 (95% CI, 1.10–3.08) to 13.15 (95% CI, 5.93–29.20), all p≤0.023. ChatGPT-5 correctly answered 17/189 items (9.0%), but fewer than half of residents were correct (“large language model-only wins”), whereas residents were more successful on items that ChatGPT-5 overlooked.
CONCLUSIONS: ChatGPT-5 outperformed ophthalmology residents on text-based glaucoma multiple-choice questions, indicating its potential as a subspecialty education and assessment tool. Generalizability is limited by the single question bank, text-only items, a small resident cohort, and the evaluation of one large language model version at a single time point. Before incorporating these findings into clinical decision-making, larger, multimodal, and longitudinal studies are required.
Keywords: Glaucoma; Artificial intelligence; Large language models; Education, medical; Medical staff, hospital
Abstract
PURPOSE: Standard automated perimetry has been the standard method for measuring visual field changes for several years. It can measure an individual’s ability to detect a light stimulus from a uniformly illuminated background. In the management of glaucoma, the primary objective of perimetry is the identification and quantification of visual field abnormalities. It also serves as a longitudinal evaluation for the detection of disease progression. The development of artificial intelligence-based models capable of interpreting tests could combine technological development with improved access to healthcare.
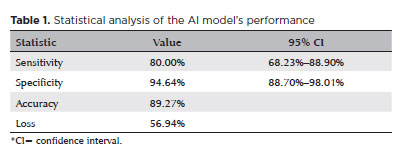
METHODS: In this observational, cross-sectional, descriptive study, we used an artificial intelligence-based model [Inception V3] to interpret gray-scale crops from standard automated perimetry that were performed in an ophthalmology clinic in the Brazilian Amazon rainforest between January 2018 and December 2022.
RESULTS: The study included 1,519 standard automated perimetry test results that were performed using Humphrey HFA-II-i-750 (Zeiss Meditech). The Subsequently, 70%, 10%, and 20% of the dataset were used for training, validation, and testing, respectively. The model achieved 80% (68.23%–88.9%) sensitivity and 94.64% (88.8%–98%) specificity for detecting altered perimetry results. Furthermore, the area under the receiver operating characteristic curve was 0.93.
CONCLUSIONS: The integration of artificial intelligence in the diagnosis, screening, and monitoring of pathologies represents a paradigm shift in ophthalmology, enabling significant improvements in safety, efficiency, availability, and accessibility of treatment.
Keywords: Glaucoma; Disease progression; Perimetry; Visual Fields; Visual field tests; Artificial intelligence; Neural networks, computers; Machine learning
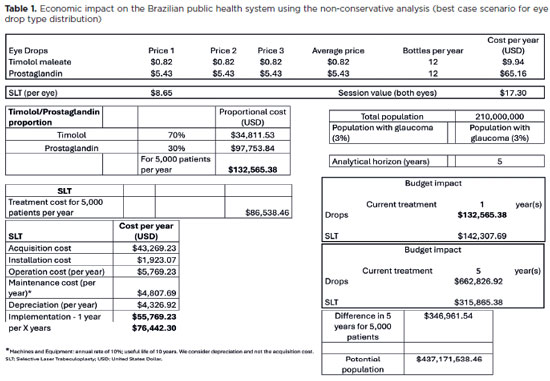
Abstract
PURPOSE: To evaluate the economic impact of the following initial treatment scenarios for glaucoma on the Brazilian Public Health System (SUS): (1) traditional continuous instillation of hypotensive eye drops and (2) single session of selective laser trabeculoplasty.
METHODS: Economic impact was analyzed in three scenarios, from the least to the most conservative, for a hypothetical cohort of 5,000 individuals with open-angle glaucoma. Thereafter, projections were made on the basis of a glaucoma prevalence of 3% in the 2021 Brazilian population size.
RESULTS: All three scenarios demonstrated that selective laser trabeculoplasty exhibited a significantly lower economic impact than the eye drops on SUS over one and five years. Furthermore, the difference was more than United States Dollar 8 billion at five years when considering 3% of the Brazilian population aged >40 years in 2021.
CONCLUSION: As the initial treatment for primary open-angle glaucoma, selective laser trabeculoplasty exhibited a lower economic impact on SUS than latanoprost and timolol maleate eye drop instillation in all the studied scenarios over one and five-year periods.
Keywords: Glaucoma; Trabeculotomy; Laser therapy; Cost analysis; Health care cost Unified Health System; Brazil
09-fig01.jpg)
Abstract
A fita de Schirmer e o swab conjunctival são utilizados na oftalmologia como métodos de coleta para lágrimas e fluidos. Durante a pandemia da COVID-19, um dos desafios foi o diagnóstico correto e se sabe que, em alguns casos, as manifestações oculares podem ser um dos primeiros sintomas. Nesse contexto, este estudo tem como objetivo levantar evidência que destaque o uso de fitas de Schirmer e de swabs conjuntivais como método de coleta para análise viral. Conduziu-se uma revisão de literatura seguindo o protocolo para Scoping Review definido pelo Joanna Briggs Institute. Os pesquisadores analisaram os estudos em busca do vírus pesquisado, os métodos de coleta e os métodos de análise. Vírus podem ser detectados na superfície ocular através da análise de fitas de Schirmer e de swabs conjuntivais, entretanto novos estudos com populações maiores e com definições claras de tempo são necessários para conclusões mais assertivas no tema.
Keywords: Antígeno de superfície/isolamento & purificação; Túnica conjuntiva; Lágrimas; Proteína do olho/análise; Manejo de espécimes; Reação em cadeia da polimerase/métodos; COVID-19; Manifestações oculares
 ABO is licensed under a Creative Commons Attribution-NonComercial 4.0 Internacional.
ABO is licensed under a Creative Commons Attribution-NonComercial 4.0 Internacional.
About
Issues
Editorial Board
Submission
Arquivos Brasileiros de Oftalmologia
Official publication of Brazilian Council of Ophthalmology - Conselho Brasileiro de Oftalmologia (CBO)
Rua Casa do Ator, 1.117 - 2nd floor - Zip Code: 04546-004
São Paulo - SP, Brazil
TEL: +55 11 3266-4000
E-mail: [email protected]